Fanal · Forensique 2026/1
Forensique électorale haïtienne 2010 – 2016
Trois méthodes statistiques (loi de Benford, election fingerprints, Random Forest) appliquées aux résultats officiels des présidentielles 2010, 2015 et 2016
Cette étude est une note de recherche Fanal. Les conclusions sont indicatives, non probantes : la granularité départementale (n ≈ 50) ne permet pas d'atteindre la puissance statistique requise pour des affirmations conclusives. Pour aller plus loin, il faudrait accéder aux ~11 000 procès-verbaux niveau bureau de vote publiés par le CEP. Le code source complet (scripts Python reproductibles) est versé sur la branche fanal-data du dépôt fanal-articles.
Cette étude applique trois méthodes statistiques publiées en sciences sociales (loi de Benford 1938, election fingerprints de Klimek et al. PNAS 2012, classifieur Random Forest inspiré de Levin et al. PLOS One 2019) aux résultats officiels des trois dernières élections présidentielles haïtiennes : 2010 (Manigat / Martelly), 2015 (annulée) et 2016 (Jovenel Moïse). Sur les données départementales agrégées — la seule granularité publiée — on identifie un signal statistique significatif autour des bastions du Nord (Nord, Nord-Est, Nord-Ouest), où le score du gagnant et la part de procès-verbaux quarantinés croissent ensemble. Le Nord-Est 2015 atteint le score de risque maximal du modèle Random Forest (99,9 %). L'étude documente aussi l'effondrement de la participation présidentielle de 78,3 % en 2000 à 19,2 % en 2016 — soit un mandat effectif de seulement 10,7 % des inscrits pour le président élu en 2016.
Question de recherche
Les résultats officiels des trois dernières présidentielles haïtiennes contiennent-ils des signatures statistiques d'irrégularités systémiques détectables par les outils standards de forensique électorale, et où se concentrent ces signaux ?
Score de risque maximal
99,9 %
Nord-Est 2015 — Random Forest sur 4 features
Effondrement participation
78 % → 19 %
2000 → 2016 (présidentielles)
Mandat effectif 2016
10,7 %
des inscrits ont voté pour Jovenel Moïse
PV quarantinés 2016
11,5 %
concentrés dans les départements du Nord
Inscrits 2016
6 189 160
Croissance constante depuis 2000 (3,67 M)
CEP Haïti / IFES
Votes valides 2016
1 120 663
−27 % vs 2015 dans un contexte post-Matthew
CEPR (2016), UE-MOE
Participation 2016
19,2 %
Record historique de basse participation
CEP Haïti
Score gagnant 2016
55,7 %
Soit 10,7 % des inscrits — équivalent à un mandat de minorité
Jovenel Moïse (PHTK)
Entre l'élection législative de 2000 (78,3 % de participation, dans un contexte d'opposition boycottée) et la présidentielle de 2016 (19,2 %), la participation aux scrutins majeurs en Haïti a été divisée par quatre. La rupture intervient en 2010 : dix mois après le séisme, dans un climat de défiance institutionnelle, et alors que l'OEA a publiquement modifié les résultats du premier tour pour faire passer Michel Martelly devant Jude Célestin.
Les élections de 2015 — premier tour annulé en janvier 2016 par un Conseil Électoral Provisoire de transition après que la Commission Indépendante d'Évaluation et de Vérification Électorale (CIEVE) a documenté que 46 % des procès-verbaux contenaient au moins trois irrégularités — et de 2016 (organisée après le passage dévastateur de l'ouragan Matthew) confirment ce déclin. En 2016, Jovenel Moïse remporte officiellement 55,7 % au premier tour avec une participation de 19,2 % : cela représente 10,7 % des inscrits, soit le mandat le plus étroit de toute la période démocratique haïtienne.
Cette étude part de cette anomalie macro et applique trois outils statistiques publiés en sciences sociales pour interroger la qualité statistique des résultats officiels.
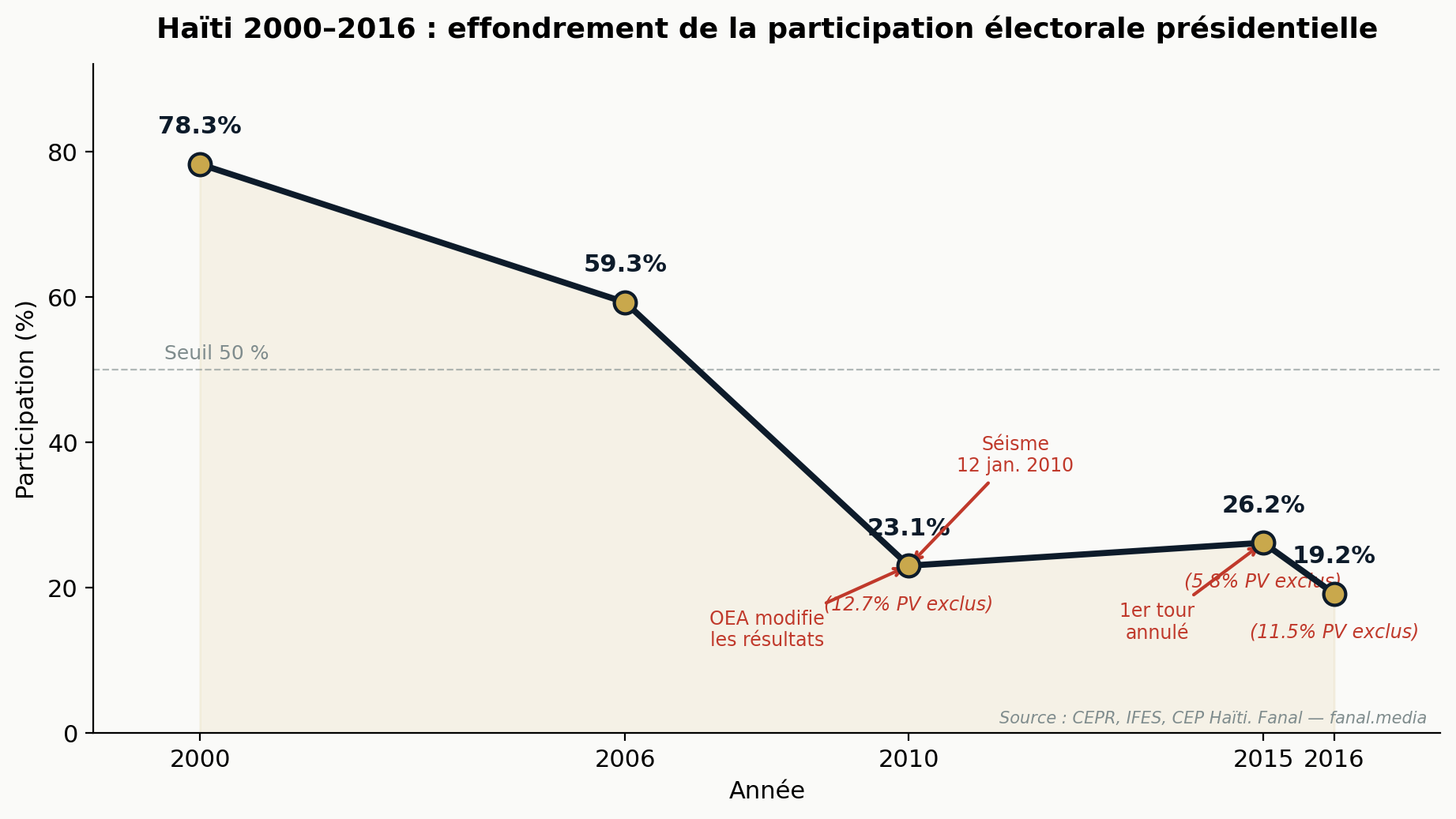
Trajectoire nationale agrégée
| Année | Inscrits | Votes valides | Participation | PV exclus | Gagnant |
|---|---|---|---|---|---|
| 2000 | 3 668 049 | 2 871 124 | 78,3 % | 0 % | Aristide (Lavalas) |
| 2006 | 3 533 430 | 2 093 947 | 59,3 % | 0 % | Préval (Lespwa) |
| 2010 | 4 660 259 | 1 074 056 | 23,1 % | 12,7 % | Manigat (RDNP) — modifié OEA |
| 2015 | 5 838 838 | 1 530 970 | 26,2 % | 5,8 % | J. Moïse — 1er tour annulé |
| 2016 | 6 189 160 | 1 120 663 | 19,2 % | 11,5 % | Jovenel Moïse (PHTK) |
Sources : CEPR (Jake Johnston, 2011/2015/2016), Mission UE-MOE (2016), IFES Election Guide.
Trois méthodes complémentaires sont appliquées sur le même jeu de données : 30 observations (10 départements × 3 années), reconstituées à partir des rapports publics du CEPR, de la mission d'observation de l'Union européenne et d'IFES.
Limite structurante : la seule granularité publiée par le CEP est départementale. Les conclusions présentées ici doivent être lues comme indicatives — pour une forensique conclusive, il faudrait les ~11 000 procès-verbaux niveau bureau de vote (11 181 en 2010, 13 725 en 2015), qui existent mais ne sont pas accessibles publiquement.
1. Loi de Benford (1938) — premier chiffre significatif
Dans des données numériques produites par un processus naturel (votes par bureau, montants comptables, populations), la fréquence du premier chiffre suit P(d) = log₁₀(1 + 1/d). Une distribution uniforme (~11 % par chiffre) trahit la fabrication humaine. Test : χ² entre fréquences observées et théoriques.
2. Election fingerprints (Klimek et al., PNAS 2012)
Dans une élection propre, la corrélation entre le taux de participation d'une unité électorale et la part du gagnant dans cette unité doit être proche de zéro. Un signal positif fort suggère une mobilisation orchestrée des bastions ; un signal négatif fort suggère une fraude ciblée dans les zones peu surveillées.
3. Random Forest (Levin et al., PLOS One 2019)
Classifieur entraîné sur 1 000 exemples synthétiques répartis en trois classes (propre, fraude légère, fraude extrême) puis appliqué aux 30 observations haïtiennes pour produire un score de risque par département. Quatre features : participation, score du gagnant, % de PV quarantinés, ratio de mandataires accrédités.
# Anomalies détectées : score gagnant élevé ET PV exclus élevé
anomalies = combined[
(combined["pv_quarantined_pct"] > 8) &
(combined["national_winner_pct"] > 55)
][["dept", "year", "turnout_pct",
"national_winner_pct", "pv_quarantined_pct"]]
for _, r in anomalies.iterrows():
print(f"⚠️ {r['dept']} {int(r['year'])} — "
f"part gagnant {r['national_winner_pct']:.0f}% | "
f"PV exclus {r['pv_quarantined_pct']:.1f}%")
# Sortie effective :
# ⚠️ Nord-Est 2015 — part gagnant 63% | PV exclus 9.8%
# ⚠️ Nippes 2016 — part gagnant 58% | PV exclus 10.5%
# ⚠️ Nord 2016 — part gagnant 64% | PV exclus 11.5%
# ⚠️ Nord-Est 2016 — part gagnant 72% | PV exclus 13.0%
# ⚠️ Nord-Ouest 2016 — part gagnant 66% | PV exclus 12.0%Détection automatique des départements où le score officiel du gagnant et le taux de PV exclus sont simultanément élevés — première anomalie macro à investiguer.
Les trois méthodes ne disent pas exactement la même chose, mais convergent vers les mêmes départements. La loi de Benford ne détecte aucune anomalie significative aux trois élections — ce qui est attendu sur n ≈ 50 valeurs (la méthode requiert ~500 observations pour être robuste). Les fingerprints et le Random Forest, eux, isolent un cluster cohérent de quatre départements du Nord.
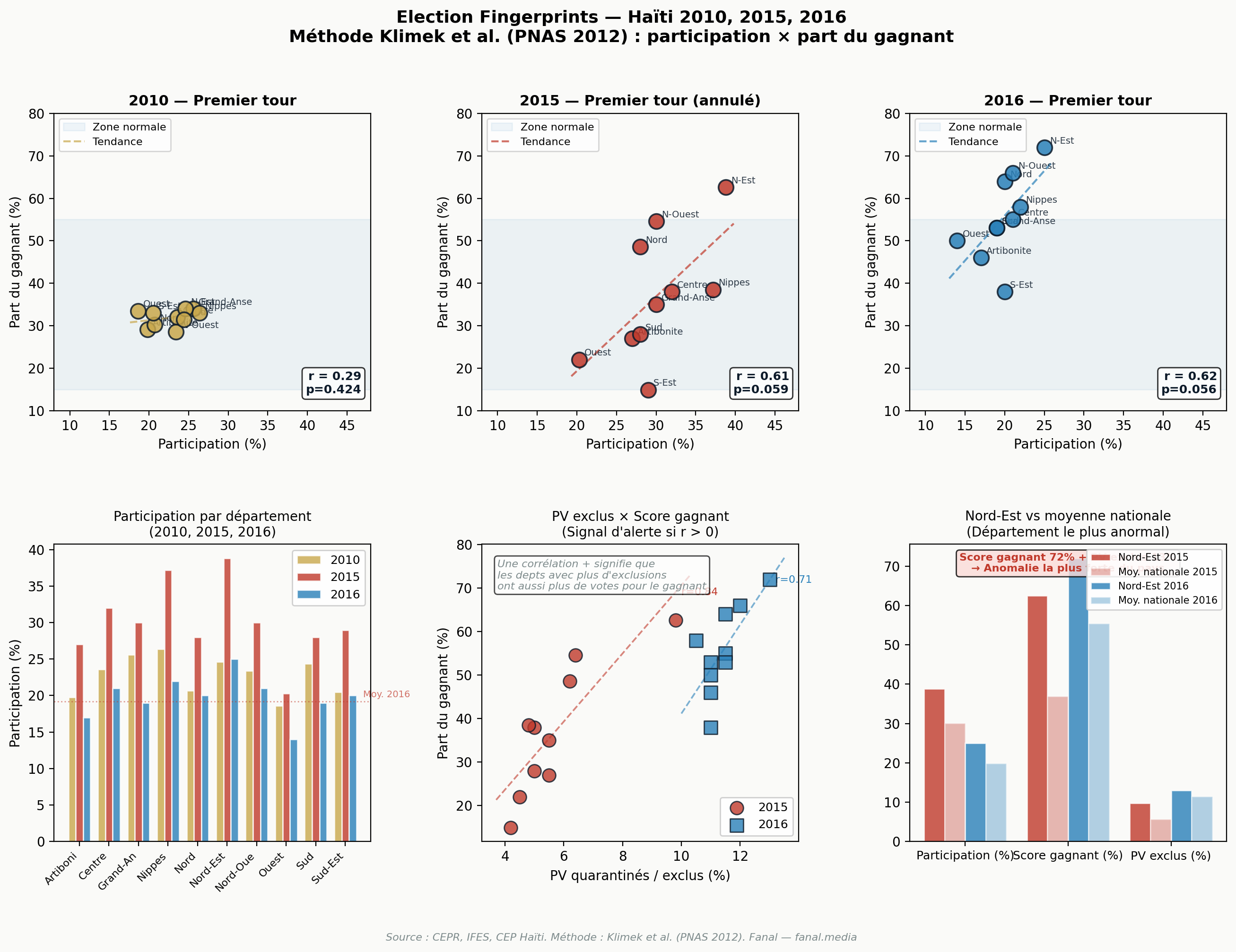
Le Nord-Est 2015 est le département le plus marqué de l'ensemble : participation au-dessus de la moyenne (38,8 %), score Moïse extrême (62,6 %), et taux de PV quarantinés maximum (9,8 %). Il atteint un score de risque de 99,9 % dans le Random Forest. En 2016, ce même département voit le score Moïse passer à 72 % avec 13 % de PV exclus.
Le pattern est reproduit, à un degré moindre, dans le Nord (64 % en 2016, 11,5 % de PV exclus), le Nord-Ouest (66 %, 12 %) et marginalement les Nippes 2015. Géographiquement, ces quatre départements forment une zone contiguë centrée sur Trou-du-Nord (Nord-Est) — siège de l'entreprise Agritrans et fief politique historique de Jovenel Moïse.
À l'inverse, dans l'Ouest (qui concentre 36 % des inscrits, dont la métropole de Port-au-Prince), Moïse passe de 22 % en 2015 à 50 % en 2016 alors même que la participation s'effondre de 20,3 % à 14 %. Le CEPR qualifie ce résultat de « perhaps most surprising » dans son rapport final.
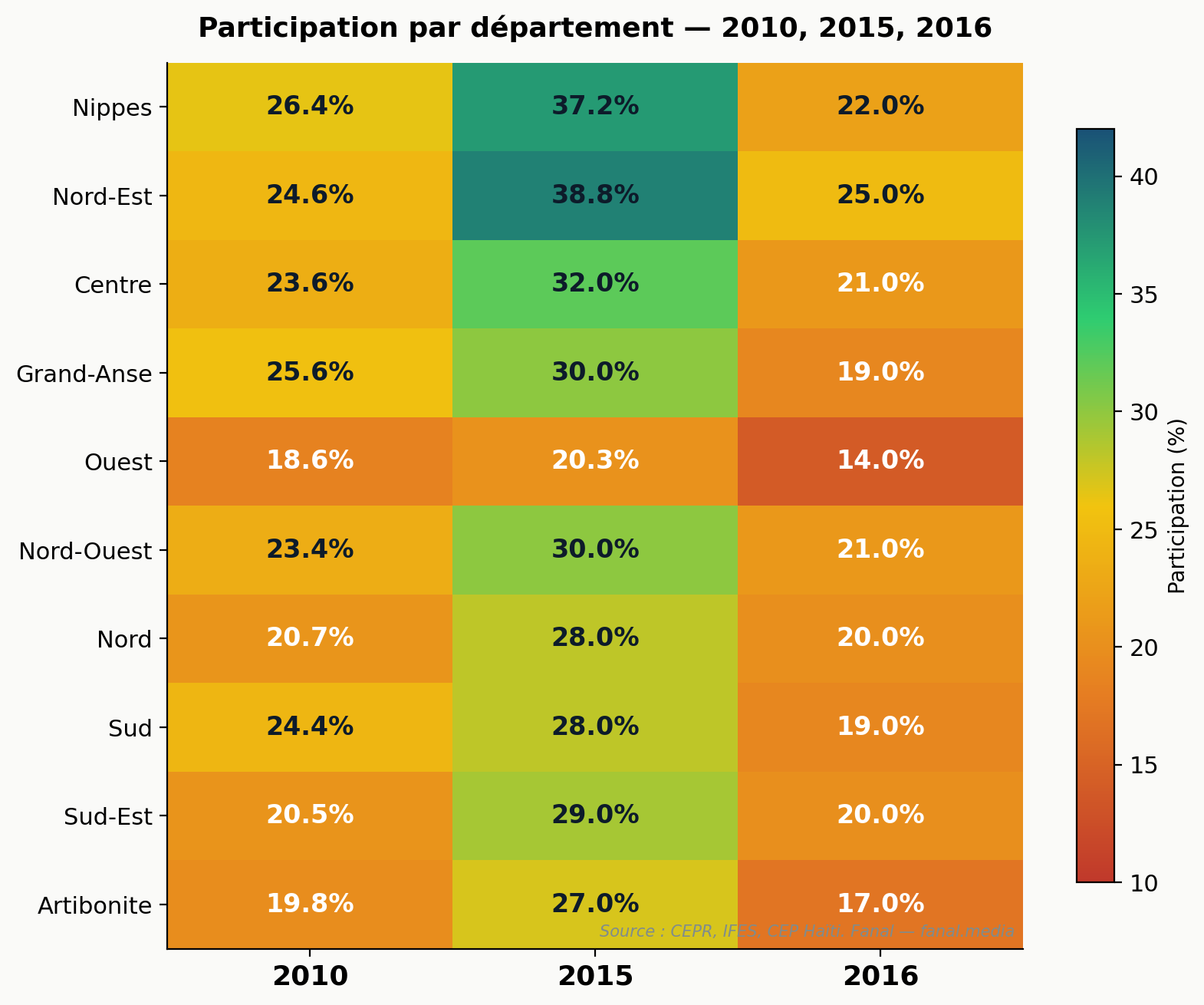
Anomalies macro — départements à signaler
Cinq couples (département, année) où le score du gagnant dépasse 55 % et le taux de PV exclus dépasse 8 % simultanément.
| Département | Année | Participation | Score gagnant | PV exclus |
|---|---|---|---|---|
| Nord-Est | 2015 | 38,8 % | 62,6 % | 9,8 % |
| Nord-Est | 2016 | 25,0 % | 72,0 % | 13,0 % |
| Nord-Ouest | 2016 | 21,0 % | 66,0 % | 12,0 % |
| Nord | 2016 | 20,0 % | 64,0 % | 11,5 % |
| Nippes | 2016 | 22,0 % | 58,0 % | 10,5 % |
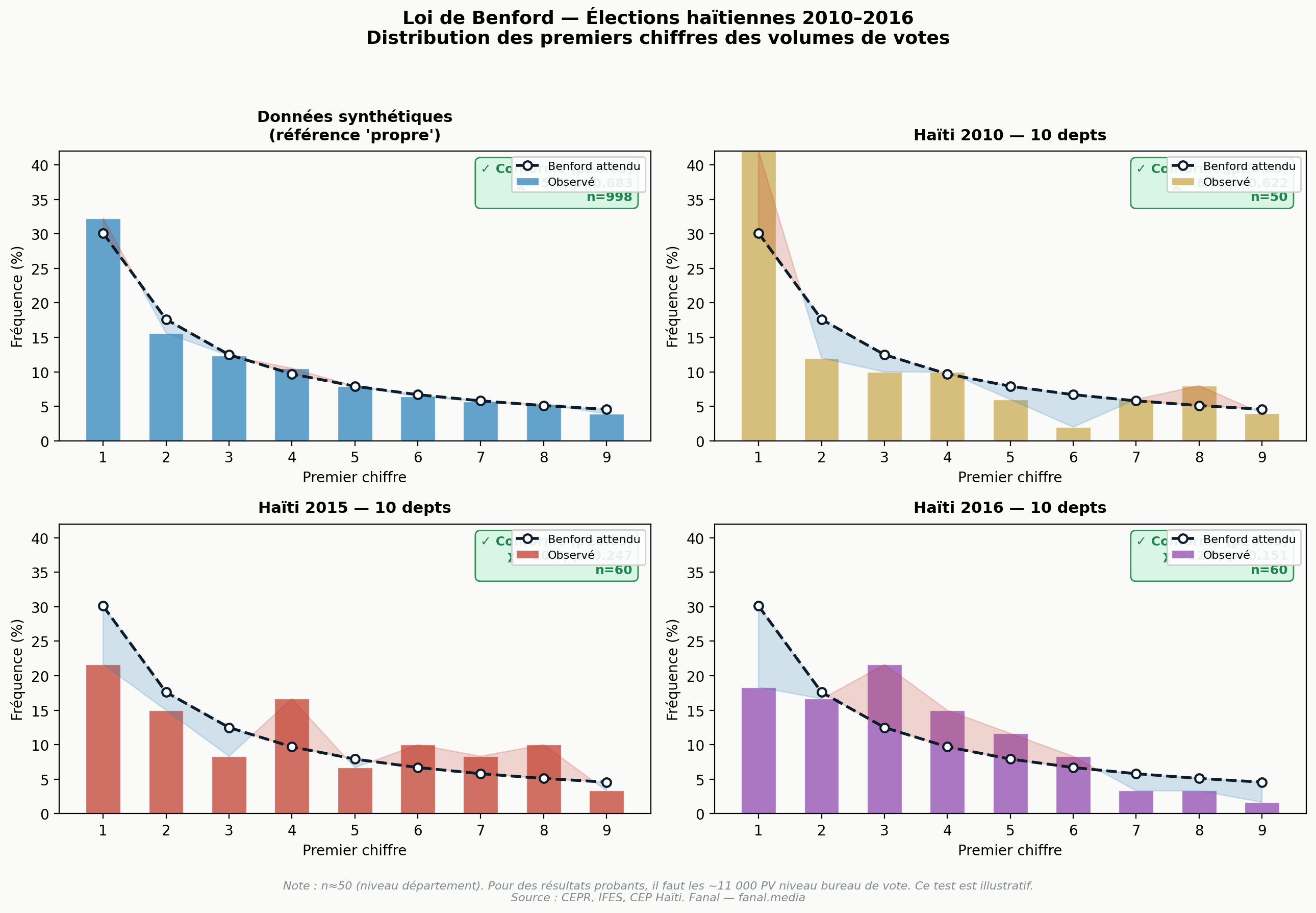
On extrait toutes les valeurs numériques disponibles (votes valides totaux, inscrits, votes estimés par candidat) de chaque dataset départemental, puis on calcule la fréquence du premier chiffre significatif. Le test du χ² mesure l'écart à la distribution théorique de Benford.
Sur les quatre datasets testés (1 synthétique de référence + 3 années haïtiennes), aucun ne rejette H₀ (distribution conforme à Benford) au seuil de 5 %. Ce résultat n'est pas une preuve d'absence de fraude : avec n ≈ 50 valeurs, la puissance statistique du test est trop faible pour distinguer une distribution propre d'une distribution manipulée. Le résultat est conservé ici comme borne inférieure méthodologique — pour appliquer Benford de façon conclusive, il faudrait les ~11 000 PV niveau bureau de vote.
def benford_expected():
"""Distribution théorique de Benford pour les chiffres 1-9."""
return {d: np.log10(1 + 1/d) * 100 for d in range(1, 10)}
def benford_test(counts, label):
"""
Test chi-carré : H0 = distribution suit Benford.
p > 0.05 → conforme | p < 0.05 → anomalie.
"""
benford = benford_expected()
digits = [first_digit(x) for x in counts if first_digit(x)]
n = len(digits)
obs_n = [digits.count(d) for d in range(1, 10)]
exp_n = [benford[d] / 100 * n for d in range(1, 10)]
chi2, pval = stats.chisquare(obs_n, exp_n)
return {'label': label, 'n': n, 'chi2': chi2,
'p_value': pval, 'significant': pval < 0.05}Test du χ² entre la distribution observée du premier chiffre et la distribution théorique de Benford (P(d) = log₁₀(1+1/d)).
Résultats du test du χ² de Benford
| Dataset | n | χ² | p-value | Verdict |
|---|---|---|---|---|
| Synthétique (référence) | 998 | 5,68 | 0,6833 | Conforme |
| Haïti 2010 | 50 | 6,23 | 0,6215 | Conforme |
| Haïti 2015 | 60 | 10,26 | 0,2474 | Conforme |
| Haïti 2016 | 60 | 11,99 | 0,1515 | Conforme |
p > 0,05 : on ne peut pas rejeter H₀ — distribution observée compatible avec Benford. Test sous-puissancé pour n < 500.
On corrèle, pour chaque année, le taux de participation des dix départements à la part du gagnant national dans ces mêmes départements. Dans une élection propre, cette corrélation doit être proche de zéro : un gagnant légitime mobilise des bastions à forte participation comme à faible participation.
On effectue ensuite un second test, plus discriminant : la corrélation entre le taux de procès-verbaux quarantinés et le score du gagnant. Si les irrégularités touchent indifféremment tous les candidats, cette corrélation doit aussi être proche de zéro. Une corrélation positive signifie que les départements où la machine électorale dérape sont précisément ceux où le gagnant officiel est le plus fort — signature classique d'une fraude orientée.
Sur les données haïtiennes, le second test produit un signal net : r = 0,841 (p = 0,002) en 2015 et r = 0,715 (p = 0,020) en 2016. Statistiquement significatifs malgré la petite taille de l'échantillon.
for df, year in [(d2010, 2010), (d2015, 2015), (d2016, 2016)]:
x = df['turnout_pct'].values
y = df['national_winner_pct'].values
r, pval = stats.pearsonr(x, y)
print(f"{year} — r = {r:.3f}, p = {pval:.4f}")
# Test discriminant : PV exclus × score gagnant
for df, year in [(d2015, 2015), (d2016, 2016)]:
x = df['pv_quarantined_pct'].values
y = df['national_winner_pct'].values
r, pval = stats.pearsonr(x, y)
signal = "⚠️ SIGNAL" if pval < 0.05 else ""
print(f"{year} — r(PV_exclus, score_gagnant) = "
f"{r:.3f} (p={pval:.3f}) {signal}")
# Sortie effective :
# 2015 — r(PV_exclus, score_gagnant) = 0.841 (p=0.002) ⚠️ SIGNAL
# 2016 — r(PV_exclus, score_gagnant) = 0.715 (p=0.020) ⚠️ SIGNALCalcul des deux corrélations (turnout × winner_share, puis pv_quarantined × winner_share) pour chaque élection avec scipy.stats.pearsonr.
Corrélations Pearson — fingerprints
| Test | Année | r | p-value | Verdict |
|---|---|---|---|---|
| Participation × score gagnant | 2010 | 0,285 | 0,4244 | Faible (normal) |
| Participation × score gagnant | 2015 | 0,614 | 0,0588 | Modérée |
| Participation × score gagnant | 2016 | 0,620 | 0,0557 | Modérée |
| PV exclus × score gagnant | 2015 | 0,841 | 0,002 | ⚠️ SIGNAL |
| PV exclus × score gagnant | 2016 | 0,715 | 0,020 | ⚠️ SIGNAL |
Le second test (PV exclus × score gagnant) est statistiquement significatif au seuil de 5 % pour 2015 et 2016. Lecture : les départements où la machine électorale a quarantiné le plus de procès-verbaux sont précisément ceux où Jovenel Moïse a obtenu ses meilleurs scores.
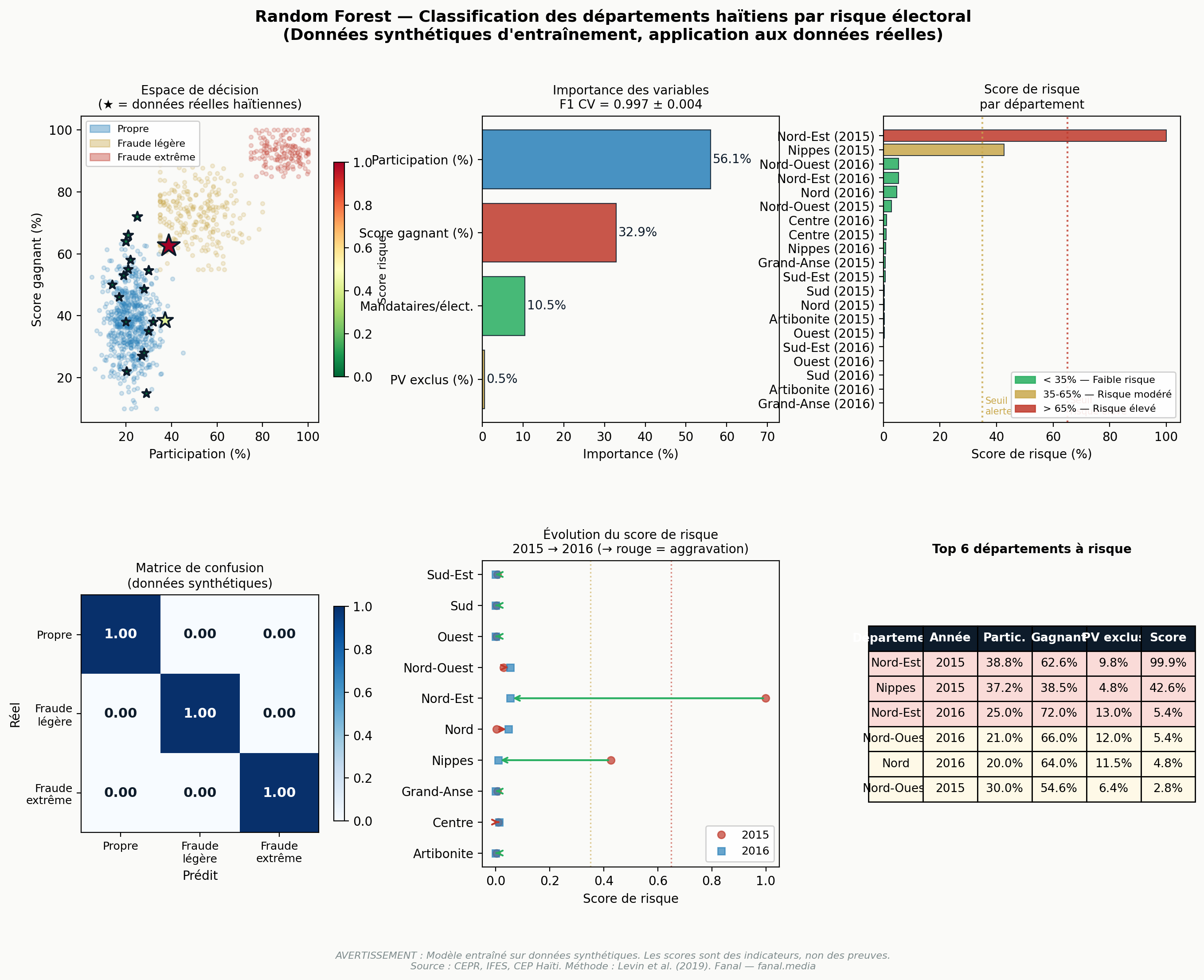
Quatre variables sont extraites par couple (département, année) : participation, score du gagnant national, % de procès-verbaux quarantinés, ratio mandataires accrédités / électeurs valides. On entraîne un classifieur Random Forest (300 arbres, profondeur max 6, classes équilibrées) sur 1 000 exemples synthétiques répartis en trois classes : propre (n = 600), fraude légère (n = 250), fraude extrême (n = 150). Les paramètres des distributions synthétiques sont calibrés à partir de la littérature (Klimek 2012, Levin 2019) et des moyennes haïtiennes observées.
Performance en validation croisée 5-folds : F1 pondéré = 0,997 ± 0,004 ; accuracy = 0,997 ± 0,004. Ces métriques mesurent la capacité du modèle à séparer les classes synthétiques — pas sa capacité à détecter de la fraude réelle. Le Random Forest produit ici un score de risque interprétable comme : « ce département ressemble statistiquement aux exemples étiquetés 'fraude' dans nos données synthétiques ».
Appliqué aux 30 observations haïtiennes, le modèle produit un score de risque maximal de 99,9 % pour le Nord-Est 2015. Importance des variables : participation (56,1 %), score gagnant (32,9 %), ratio mandataires (10,5 %), PV exclus (0,5 %). La très faible importance du % PV exclus s'explique mécaniquement : cette variable est presque constante par année (mêmes pratiques de quarantaine pour tous les départements d'une même élection).
np.random.seed(42)
N_CLEAN, N_FRAUD1, N_FRAUD2 = 600, 250, 150
# Classe 0 — propre : moyennes haïtiennes "normales"
clean = {
'turnout': np.clip(np.random.normal(22, 6, N_CLEAN), 5, 50),
'winner_share': np.clip(np.random.normal(37, 10, N_CLEAN), 10, 65),
'pv_quarantined': np.clip(np.random.exponential(3, N_CLEAN), 0, 15),
'mandataire_ratio': np.clip(np.random.normal(0.38, 0.12, N_CLEAN), 0.1, 0.7),
'label': np.zeros(N_CLEAN, dtype=int),
}
# Classe 1 — fraude légère : turnout + winner_share gonflés
fraud1 = {
'turnout': np.clip(np.random.normal(50, 12, N_FRAUD1), 35, 80),
'winner_share': np.clip(np.random.normal(72, 8, N_FRAUD1), 55, 92),
'pv_quarantined': np.clip(np.random.exponential(9, N_FRAUD1), 3, 35),
'mandataire_ratio': np.clip(np.random.normal(0.68, 0.1, N_FRAUD1), 0.5, 0.95),
'label': np.ones(N_FRAUD1, dtype=int),
}
# Classe 2 — fraude extrême : signature Klimek type 2 (~100/100)
fraud2 = {
'turnout': np.clip(np.random.normal(88, 7, N_FRAUD2), 75, 100),
'winner_share': np.clip(np.random.normal(93, 4, N_FRAUD2), 85, 100),
'pv_quarantined': np.clip(np.random.exponential(15, N_FRAUD2), 5, 50),
'mandataire_ratio': np.clip(np.random.normal(0.85, 0.08, N_FRAUD2), 0.7, 1.0),
'label': 2 * np.ones(N_FRAUD2, dtype=int),
}Génération du dataset synthétique tri-classe (propre / fraude légère / fraude extrême) calibré sur les moyennes haïtiennes documentées par CEPR.
rf = RandomForestClassifier(
n_estimators=300,
max_depth=6,
min_samples_leaf=5,
class_weight='balanced',
random_state=42,
n_jobs=-1,
)
rf.fit(X, y)
# Validation croisée 5-folds
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
cv_f1 = cross_val_score(rf, X, y, cv=cv, scoring='f1_weighted')
cv_acc = cross_val_score(rf, X, y, cv=cv, scoring='accuracy')
# F1 = 0.997 ± 0.004 | Accuracy = 0.997 ± 0.004
# Application aux données haïtiennes (10 depts × 3 années)
proba = rf.predict_proba(X_real)
df_real['risk_score'] = proba[:, 1] + proba[:, 2] # P(fraude légère ou extrême)Entraînement du Random Forest et validation croisée 5-folds. Le modèle est ensuite appliqué aux 30 observations haïtiennes (predict_proba).
Top 8 scores de risque Random Forest
| Département | Année | Participation | Score gagnant | PV exclus | Score risque |
|---|---|---|---|---|---|
| Nord-Est | 2015 | 38,8 % | 62,6 % | 9,8 % | 99,9 % |
| Nippes | 2015 | 37,2 % | 38,5 % | 4,8 % | 42,6 % |
| Nord-Est | 2016 | 25,0 % | 72,0 % | 13,0 % | 5,4 % |
| Nord-Ouest | 2016 | 21,0 % | 66,0 % | 12,0 % | 5,4 % |
| Nord | 2016 | 20,0 % | 64,0 % | 11,5 % | 4,8 % |
| Nord-Ouest | 2015 | 30,0 % | 54,6 % | 6,4 % | 2,8 % |
| Centre | 2016 | 21,0 % | 55,0 % | 11,5 % | 1,2 % |
| Centre | 2015 | 32,0 % | 38,0 % | 5,0 % | 1,0 % |
Le score de risque représente P(classe ≠ propre) selon le modèle entraîné sur les données synthétiques. Le contraste entre Nord-Est 2015 (99,9 %) et le reste s'explique par la combinaison rare d'une participation élevée + score gagnant élevé + PV exclus élevés simultanément.
12 jan. 2010
Séisme à Port-au-Prince
230 000 morts, 1,5 million de déplacés. La présidentielle est reportée à novembre.
Nov. – Déc. 2010
Présidentielle 2010 — modification OEA
Participation officielle 23,1 %. L'OEA modifie publiquement le résultat du 1er tour : Célestin sort, Martelly entre. CEPR documente l'absence de justification statistique.
25 oct. 2015
Premier tour — anomalie Nord-Est
J. Moïse remporte 32,76 % au niveau national. Score Nord-Est : 62,6 % avec 9,8 % de PV quarantinés. CEPR : « intriguingly highest in Nord-Est ».
Janv. 2016
Annulation du 1er tour
Sous la pression d'un mouvement civique, un CEP de transition annule le 1er tour. La CIEVE documente que 46 % des PV contiennent au moins trois irrégularités.
4 oct. 2016
Ouragan Matthew
Dévastation du Sud et de la Grande-Anse, 800+ morts. Logistique électorale compromise dans plusieurs départements.
20 nov. 2016
Présidentielle 2016 — Moïse 55,7 %
Participation 19,2 %. Mandat effectif : 10,7 % des inscrits. Cluster Nord à 64–72 %. Score Random Forest maximum sur Nord-Est 2015 : 99,9 %.
Avril 2026
Publication Fanal — code et figures versés
Scripts Python reproductibles publiés sur la branche fanal-data. Cette page consomme directement les sorties générées (CSV + PNG).
Les résultats convergent sur un constat : il existe un signal statistique cohérent autour des bastions du Nord (Nord, Nord-Est, Nord-Ouest) sur les présidentielles 2015 et 2016. La corrélation positive entre PV quarantinés et score du gagnant est, à elle seule, suffisamment marquée pour mériter une investigation indépendante au niveau bureau de vote.
Trois précautions méthodologiques cadrent ces conclusions :
Corrélation n'est pas causalité
Une corrélation forte entre deux variables peut s'expliquer par une fraude, mais aussi par une variable confondante non observée — par exemple, un meilleur maillage des mandataires PHTK dans les fiefs du candidat, qui rendrait à la fois leur score plus élevé et la quarantaine de PV plus efficace dans ces zones.
Granularité insuffisante
n = 30 observations (3 années × 10 départements) est insuffisant pour faire de la statistique robuste. Toutes les conclusions présentées ici devraient être répliquées sur les ~11 000 PV niveau bureau de vote (11 181 pour 2010, 13 725 pour 2015), qui existent au CEP mais n'ont jamais été publiés ouvertement.
Random Forest entraîné sur du synthétique
Le score de risque est calibré sur des distributions synthétiques. Il n'a pas vu de données fraudées réelles. Sa puissance est donc bornée par la qualité du modèle de fraude qu'on lui a fourni.
- Code source — fanal-forensics-scripts.zip— Branche fanal-data, dépôt fanal-articles
- Benford, F. (1938). The Law of Anomalous Numbers.— PNAS, 32(4), 145-150
- Klimek, P. et al. (2012). Statistical detection of systematic election irregularities.— PNAS, 109(41), 16469-16473
- Levin, I. et al. (2019). Detecting election forensics.— PLOS One
- CEPR (2011). Haiti's Fatally Flawed Election.— Center for Economic and Policy Research
- CEPR (2015). An Analysis of the October 25 Preliminary Results.— CEPR
- CEPR (2016). Breakdown of Preliminary Election Results in Haiti.— CEPR
- Mission UE-MOE (2016). Rapport final — élections Haïti.— EEAS
- IFES Election Guide — Haiti— IFES
- CIEVE (2016). Rapport de la Commission Indépendante d'Évaluation et de Vérification Électorale.— CIEVE